Training robust bimanual manipulation policies via imitation learning requires demonstration data with broad cov- erage over robot poses, contacts, and scene contexts. However, collecting diverse and precise real-world demonstrations is costly and time-consuming, which hinders scalability. Prior works have addressed this with data augmentation, typically for either eye-in- hand (wrist camera) setups with RGB inputs or for generating novel images without paired actions, leaving augmentation for eye-to-hand (third-person) RGB-D training with new action labels less explored. In this paper, we propose Synthetic Robot Pose Generation for Bimanual Data Augmentation (ROPA), an offline imitation learning data augmentation method that fine-tunes Stable Diffusion to synthesize third-person RGB and RGB-D observations of novel robot poses from a single camera viewpoint. Our approach simultaneously generates corresponding joint- space action labels while employing constrained optimization to enforce physical consistency through appropriate gripper-to-object contact constraints in bimanual scenarios. We evaluate our method on 5 simulated and 3 real-world tasks. Our results across 2625 simulation trials and 300 real-world trials demonstrate that ROPA outperforms baselines and ablations, showing its potential for scalable RGB and RGB-D data augmentation in eye-to- hand bimanual manipulation.
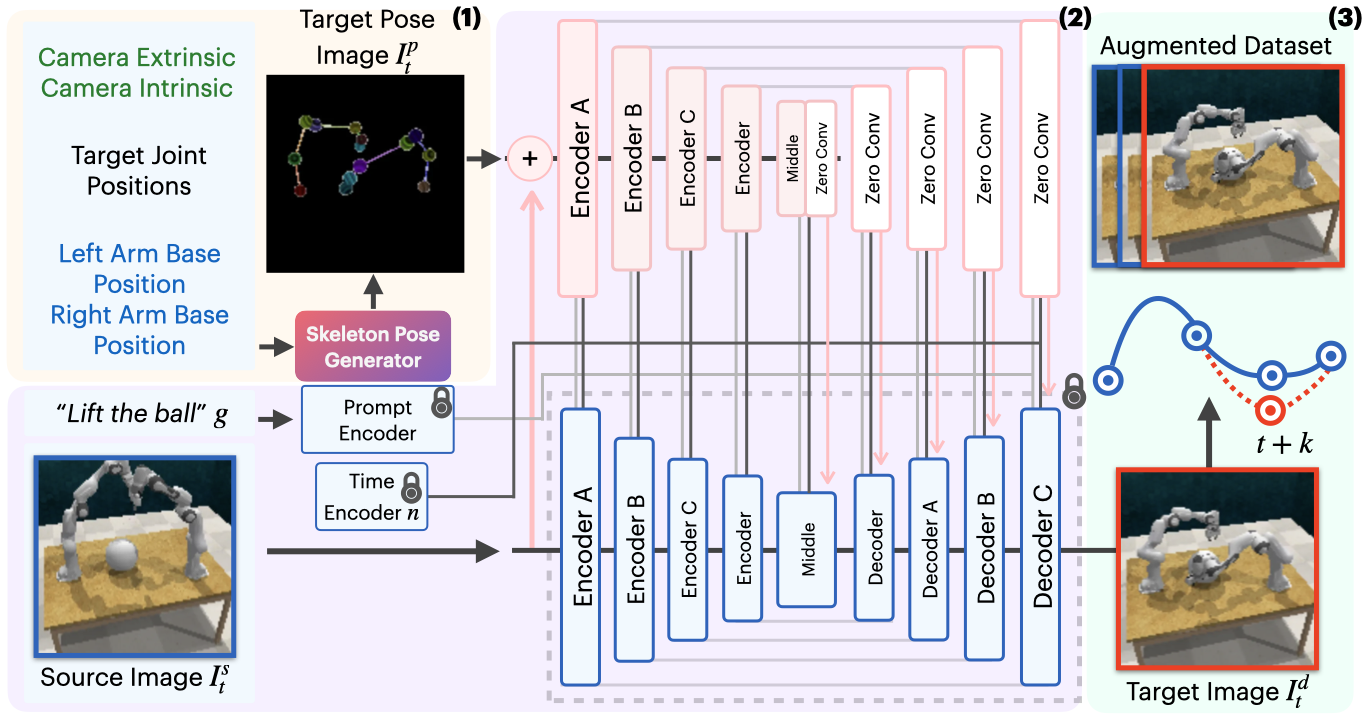
(1) The Skeleton Pose Generator takes camera extrinsics and intrinsics, target joint positions, and left and right robot base positions to generate a skeleton pose image \(I_t^{p}\) representing the desired joint configuration.
(2) The source image \(I_t^s\) and language goal \(g\) are fed into Stable Diffusion, while the generated skeleton pose serves as control input to ControlNet, producing the target image \(I_t^{d}\). The locked icons represent locked parameters.
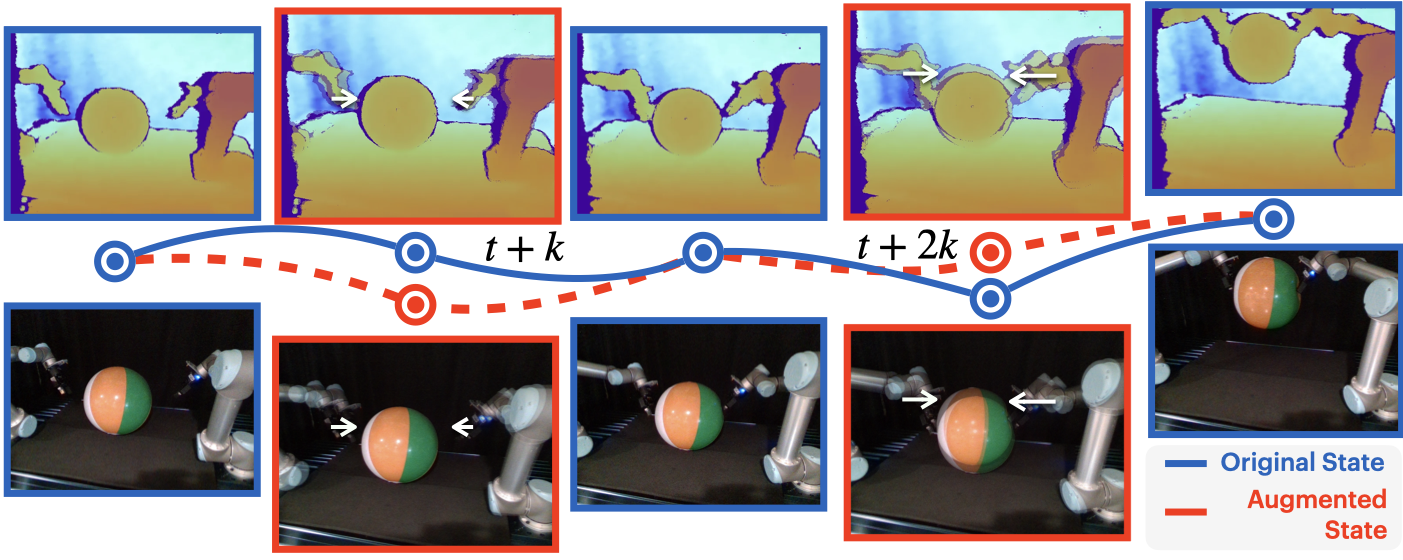
(3) The original dataset is duplicated and generated target states replace the original states every \(k\) timesteps (at \(t+k\), \(t+2k\), etc.), with updated corresponding action labels. This augmented dataset is combined with the original dataset to train a bimanual manipulation policy.
We demonstrate ROPA's ability to generate diverse robot poses by sampling end-effector positions in different directions. The left image in each figure shows the target skeleton pose representation, while the right image displays the corresponding generated image.
Random End-Effector Poses Moving Upward
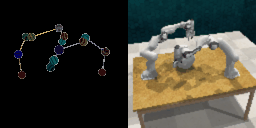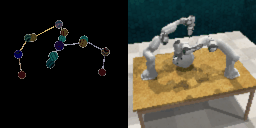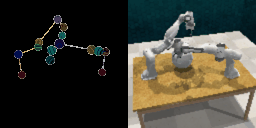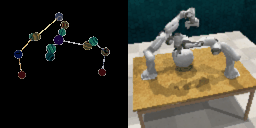
Random End-Effector Poses Moving Rightward

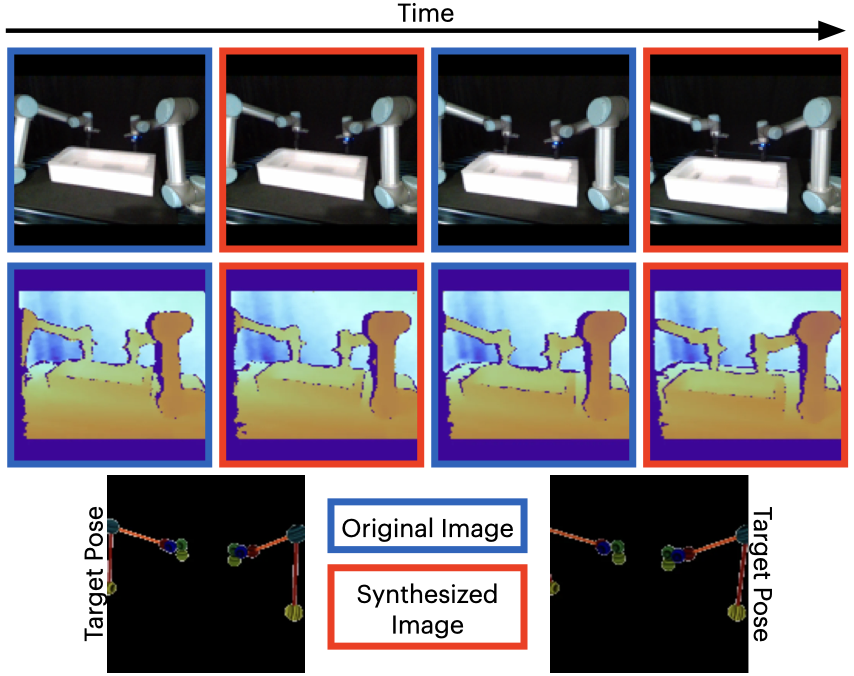
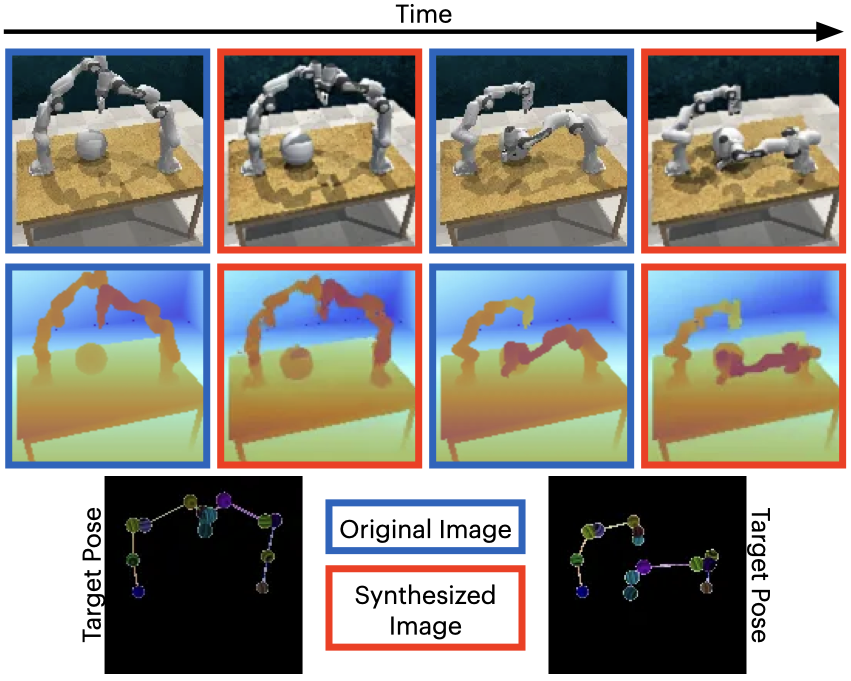
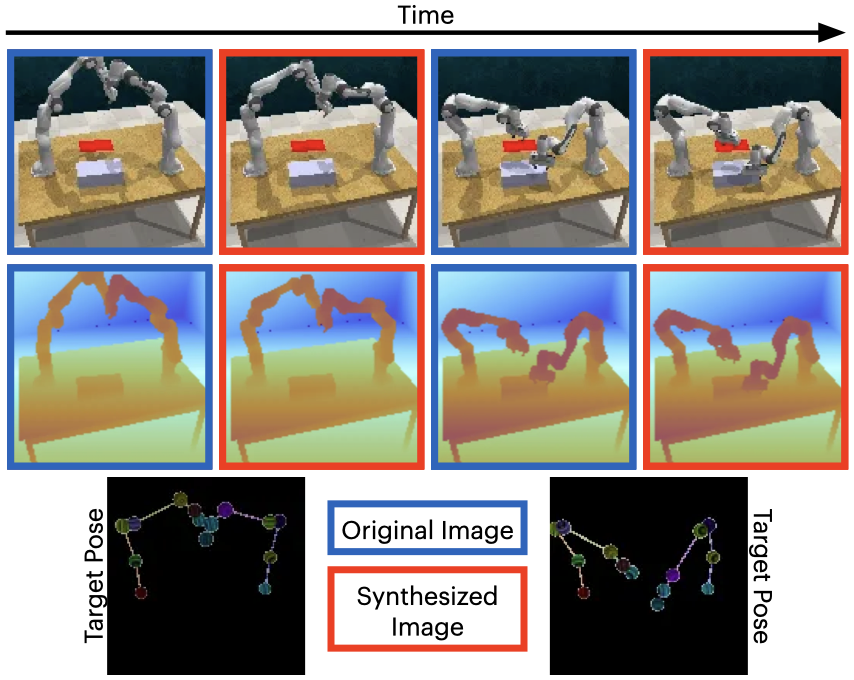
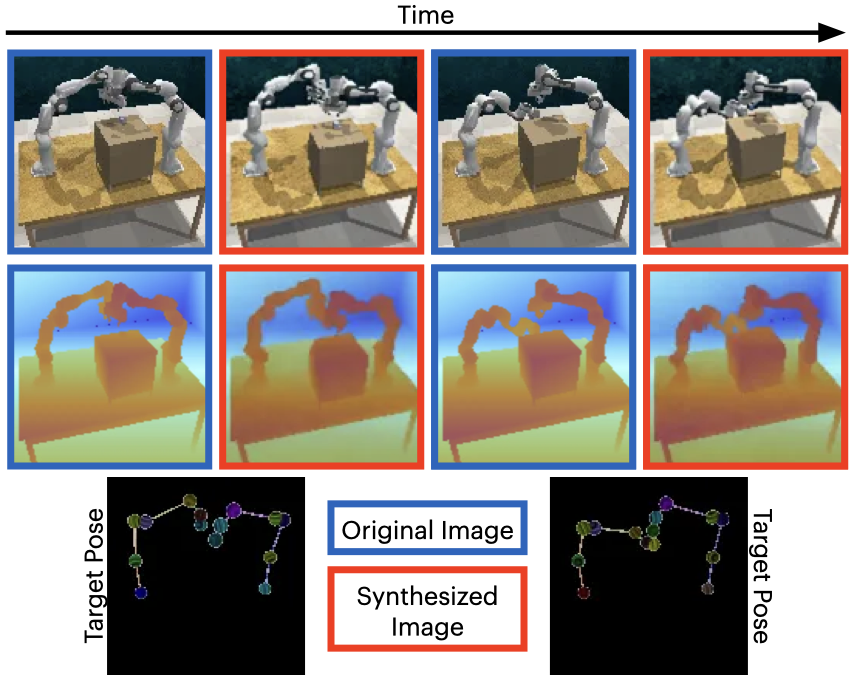
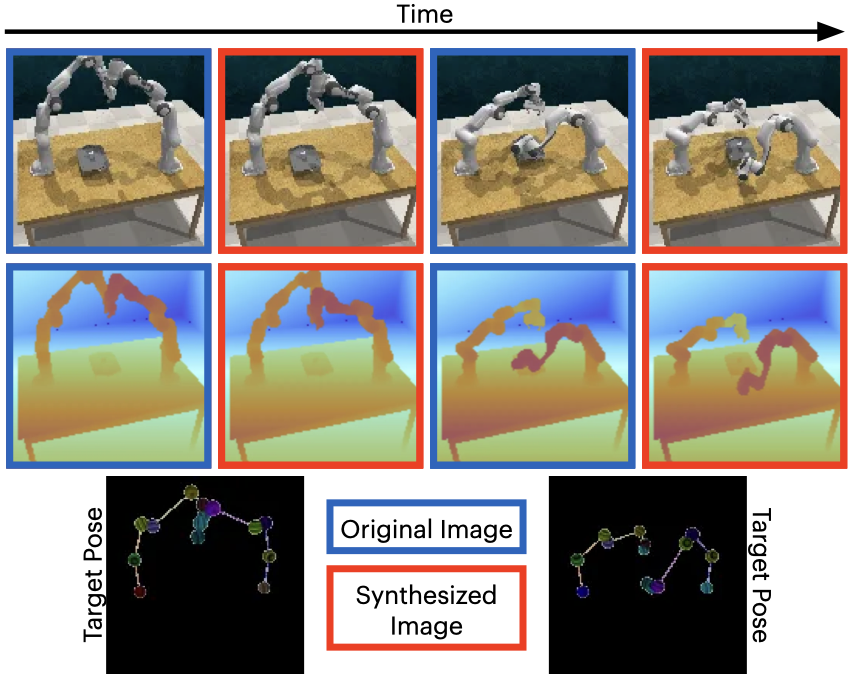
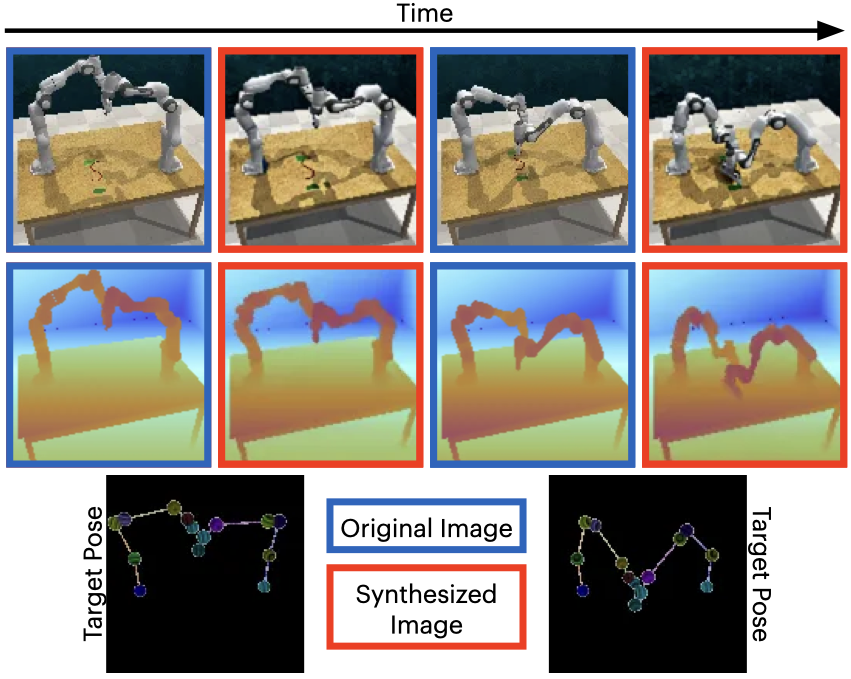
We present synthesized images from various bimanual tasks across two timesteps.
Real-World
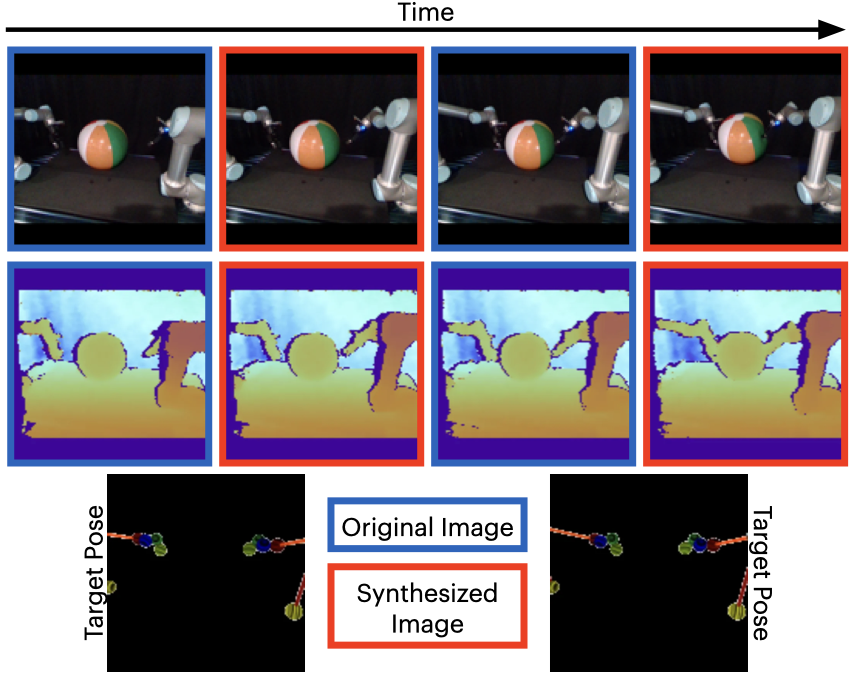
The dark bordered images show the original RGB and RGB-D images, while the red bordered images represent the generated target image RGB and RGB-D images conditioned on the corresponding skeleton pose shown below.
These are rollout comparisons between the ROPA (left) and ACT without data augmentation (right). In all rollouts, ACT without augmentation froze, whereas ROPA succeeded.
Compare results between ROPA, ACT with no augmentation, ACT with more data, and Fine-Tuned VISTA across various tasks.
These are real-world expirements with different variations for each task using ROPA.
Added various different fruits as distractors
Added various different fruits as distractors
Added various different fruits as distractors
Added one block on top of the original block